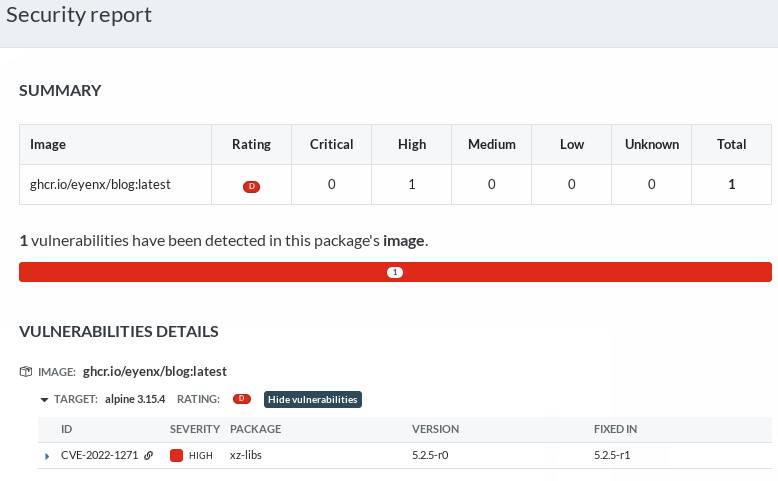
And here we go again. The second year in a row I find myself on a train directed to Bruxelles, Belgium. I will join the mass of hackers an professionals grouping at the Université libre de Bruxelles for this year’s FOSDEM.
I went through the schedule and bookmarked the most suited talks for me, while knowing that this won’t be a fixed program as rooms get pretty full and I’ll have to have a second plan ready.
Saturday, 1st February 2020
My day starts with the welcome talk in Janson. The room is nearly full. The rules get explained by the staff and after a short introduction we get to the real talks.
Podman
I get as quickly as possible in the containers devroom. I know leaving and entering this room again will be really hard, as it attracts an enormous amount of people.
Sascha Grunert presents us Podman with some cool slides and I have already some takeaways from it.
As an example you can share PID namespaces with podman between containers
podman run --pid container:containername --name myname -d alpine
Podman, as the names tells us, can create even pods on a single node:
podman pod create --name mypod
We can than start a new container inside this pod
podman run --pod mypod alpine command
And from that, we can generate kubernetes manifests:
podman generate kube -f pod.yml mypod
and obviously replay those inside podman:
podman play kube pod.yml
Lazy distribution of container images
Akihiro Suda is the next guy showing up in the container devroom. He shows us some interesting new way of running container images, by downloading first what is really needed by the container so that it can start up faster. It reduces start up time of a container by a factor of 5.
The project is based on stargz (seekable tar.gz) from Brad Fitzpatrick (Ex-Googler). The idea behind it is having an index.json inside the archive to make a direct search of files possible.
The plugin is available here.
ONLYOFFICE talk
I get out of the container devroom to go to building AW and listen to some talks on collaborative applications. The first one is the ONLYOFFICE team showing up and explaining to us how it’s application works and how well they can be integrated into Nextcloud.
They also talk about how many features they still want to implement. I didn’t even know it was possible to have such a big feature list for a collab app.
Nextcloud Hub
Nextup is Nextcloud regarding it’s new HUB feature, where they install all default applications (mail, calendar etc.) by default.
This video recaps the talk pretty good.
Live migration of containers
Yes, I’m back in the container devroom again. This time it was pretty hard to get in, as the queue was very long, but in the end, I succeeded.
Thanks to CRIU and Adrian Rebers talk I know now how to live migrate a container from one host to the other (with it’s memory!)
Go check the recording of the talk out, as he has also a demo in it.
Hint: there is a podman container checkpoint command
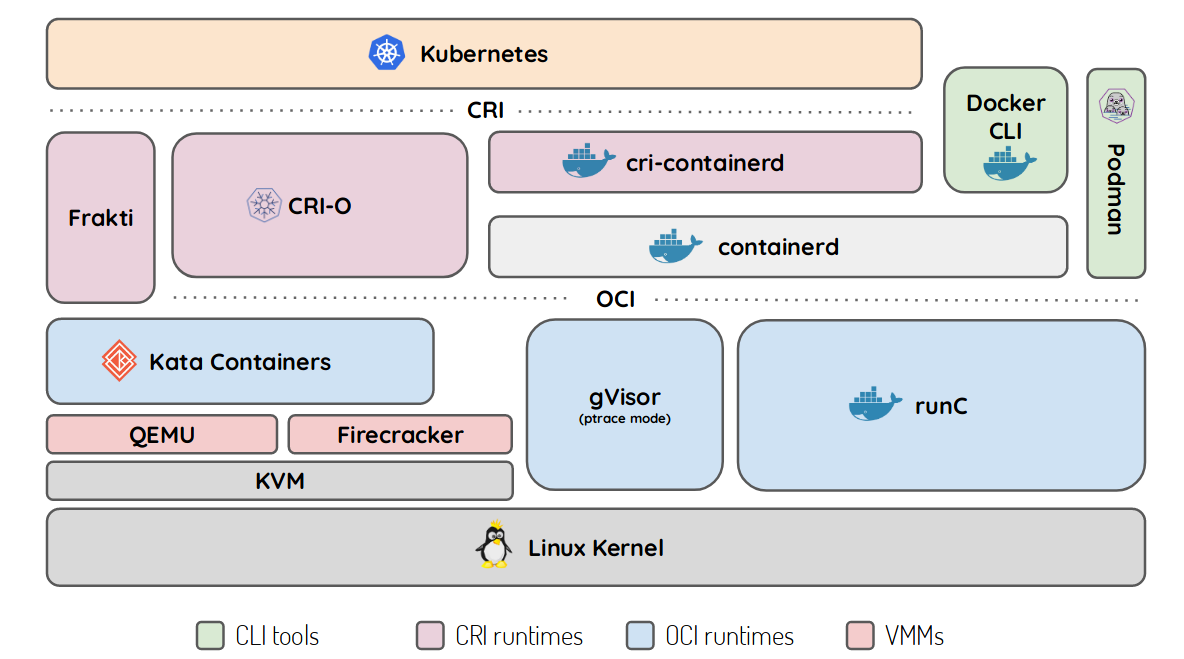
Below K8s: Demystifying container runtimes
Thierry Carrez started drawing a dashboard some years ago to show how K8s works to make containers run. He started adding stuff as CRI and OCI came along and the final drawing he ended up with, is quite helpful for some folks.
Immutable Deployments
Matteo Valentini shows us that Kubernetes isn’t always the solution to a problem. With his toolchain consisting of Git, Terraform, Ansible and Packer he convinces us how easy it is to have immutable deployments and go for an approach of a full CI/CD pipeline, starting by building a cloud image with Packer and Ansible and deploying it to the cloud with Terraform.
Go check out is (not yet documented) GitHub repo.
Kubernetes Clusterf*ck
Kris Nova. This is the highlight for me. The room in building K is already quite full as I get in. Over 800 people will be listening to her.
She gets quite technically and hacks during her 50 minutes talk a Kubernetes cluster as a normal cluster user. By using a privileged container, she manages to gain control of the whole Kubernetes cluster as cluster admin. The solution? With Falco you could prevent that from happening. The talk is quite interesting and she gets a big applause at the end. Well done! Everything is obviously available on her GitHub.
SELinux with Container Runtimes
No, this time I’m not ending up in the container devroom again. It’s the security devroom. Lukas Vrabec informs us on generating SELinux policies for container with a new project called Udica. Thanks to this tool generating SELinux policies for our container will be as easy as eating cake (but I’d still rather have cake than SELinux policies).
This two commands make it look pretty easy:
podman inspect -l | udica my_container
semodule -i my_container.cil
End2End encryption in instant messaging
For the end of the day Winfried Tilanus gives a talk regarding the challenges we’re confronted when trying to get end to end encryption for instant messaging. Spoiler: it’s not that easy.
His slides are available here.
Sudo
Last but not least, Mr Czanik is up, and I can profit quite a lot from his talk. Sudo can do a lot more than just give you root access to a system. Some plugins and his demo on how sudo can also be run in pair programming/engineering gets a good round of applause.
Go check it out!
Sunday, 2nd February 2020
Close lid to encrypt
I start my day by joining the decentralized internet and privacy devroom. I will be staying in here a lot today. The first talk is about closing the lid of your laptop and actually encrypting the HD again (Encrypt on suspend). The talk gets quite technical but basically, the processes get freezed and memory saved to disk before the encryption happens. It’s quite a hack and not at all stable, but it works.
This time, the code is hosted on debian.org.
Identity Box
Wow, a decentralized identity tool! Today I will be seeing a few of those. Identity box is a little different than the others, because it comes with hardware. The demo even works well and shows us how to add a new friend to identity box. At this point I wish people were more alert about their privacy and would want something like this in their homes. Their homepage promises a lot.
Grafana Metrics linked to Loki Logs and Jaeger Traces
I switch the room and stand in line to enter the monitoring and observability track. Andrej Ocenas shows us how to correlate Loki logs with Grafana metrics and link those to traces in Jaeger and viceversa. Quite interesting to me. With this linking possiblity you get from traces to metrics and from there to logs and back very easy. Go look at his talk, he has a demo!
I listen to another talk but continue my journey back into the p2p & privacy devroom.
ID4me
As I said, another federated identity provider. This time it’s ID4me which is basically doing openID but federated.
Their homepage says it all.
GNUNet
Well, this are the talks I was waiting for. GNUNet. I’m so much into decentralized internet solutions, that I can’t decide which one is the best. As an example, I’m a weekly user of ZeroNet but GNUNet was something new for me.
It’s setup really easy on ArchLinux as there is a package for it. Martin Schwarzenbach shows us what where the challenges building this and what approach they took. I would love if this would fire up and a lot of apps would be built on it! The talk is really promising.
secushareBOX
P2P IoT! Why should we trust the cloud to control our lights, music boxes and doors in our home? This is where peer-to-peer IoT comes into play. And why not built it on GNUNet? Yes this looks to amazing to be true. But this guy, Devan Carpenter, had the idea. It’s not yet fully realised but he’s getting there! Wow, can’t w8 to try it out.
Rook
No, I’m not switching room again. It’s getting too full to switch room quickly. And then I don’t want to miss the next talks in this devroom. So,opening up my laptop it is. Watching the stream of another devroom won’t hurt. The talk of Alexander Trost goes on about rook and it’s development. Very very interesting where this guys are heading. Go check them out!
DAT Protocol, Tor, OpenPush
Of course I already knew DAT before going to Belgium. I even used it a few times. The only thing I’m missing on DAT is the multiwrite capability, but they are getting there. DAT is a protocol which gives you a very easy way to share files p2p from one client to another. Heck, it even gives you the possibility to host your webpages on the DAT decentralized web. Some browser even support browsing dat:// sites. It’s kinda like ipfs but a few aspects are different.
The Tor project needs developers. This is my main take from next talk. Alexander Færøy presents us the Tor organisation and how the teams are built. Shows us some statistics too, but the main objective of this talk is to get people to help out on the project. If you know C (I don’t) please go help or at least think about donating.
Why rely on Google to do the hole notification push thingy? This man has a point! If your Android apps have to use a proprietary software to push notifications it’s not FOSS anymore. This is why he takes the matter into his own hands and builds the OpenPush project. By the way, you should check out is homepage, he offers a lot of services if you know him.
P2P - Matrix
The room is full. What a surprise, the next talk is regarding Matrix. But this time we will be looking at the next-gen Matrix. What if you can have your homeserver on your device at any time? This means being fully peer-to-peer and not having to rely anymore on a self hosted home server. Well, that would be the dream. And the guys from Matrix are on this path. They even have a demo already out there working.
The idea was to try it out with the devroom, buy downloading a docker image and starting a go binary in the background we should be able to connect with Matthew Hodgson, who gave the talk. It didn’t work for me, as we were using a different, hotspot network I couldn’t reach from the middle of the room (apparently there were some multicast issues with the FOSDEM network).
Go check out his recording to see how cool it would be.
Red Hat Container Storage (Ceph) on OpenShift
I’m free! That is the feeling you get leaving a full room. I go back to building H and join the Red Hat guys to let me introduce to the new Red Hat Container Storage on OpenShift 4.x which is basically Rook with a Ceph Backend.
The idea is to deploy this on OpenShift itself. I would never deploy software defined storage in containers, but as it is managed by an operator from Red Hat, I will trust them. I had a lot to do with OpenShift 4.x and it looks like they got this operator thingy working for them. No installs broke until yet, and all updates went through in the end. It looks like they built a very robust Kubernetes platform with OSCP 4.x.
To get Ceph now running, you bootstrap a few new nodes (on the cloud or baremetal) and define them as storage only. No other applications will run on them. Then the Operator takes over from there and deploys all Rook/Ceph components on them, in containers. I even asked if you could attach to the operator a pre-existing baremetal Ceph installation. And their answer was: “not yet, but we want to get there”.
Maddog, 20 years of FOSDEM and closing
And it’s already Sunday 4 PM. Time to get back into Janson and listen to the great Jon ‘maddog’ Hall. This guy is extraordinary! Last year I was nearly crying at the end of his talk. He always has way too many slides and way too many side jokes ready to entertain us.
This year he shows us what it was back in the day to work for FOSS, and how hard it was to make money out from it. I realize how lucky we are today. Opensource software is recognized that much and enterprises all over the world want to work with said software. But back in maddog’s early years, that wasn’t the case. Jumping from one lawsuit to the next he showed us what where the main events from the years 1970 - 2020.
Go checkout out the recording, it will be surely worth a look!
And there comes also Steven Goodwin into play. 19 attended FOSDEM and counting. This guy saw it all and presents us also the one guy who started it all. Raphael Bauduin. Who is in fact wearing the same shirt he wore at the first FOSDEM. What a bunch of nerds, I think for myself. Well I’m one too sitting here with my notebook full of stickers and copyleft hoodie.
The Staff presents to us ,without the beamer, as it had malfunctioning, the facts and numbers of this year’s FOSDEM. This is always nice to listen too, as it shows us how much time and money goes into such a project. At this point I just want to say thank you to all volunteers. We’ll see each other next year! PS: perhaps I’ll finally be able to grab a hoodie next time!

]]>